 返回
发布
返回
发布





特斯拉或将利用大车队培育自动驾驶神经网络
2020-03-25 08:15:00
据外媒报道,电动汽车制造商特斯拉已经申请了一项专利,内容是如何从其庞大的客户车队中获取训练数据,以训练其自动驾驶神经网络。
这项专利是为特斯拉申请的,但特斯拉人工智能和自动驾驶软件主管安德烈·卡帕西(Andrej Karparis)被指定为该申请的唯一发明人。

卡帕西描述了在应用程序中为深度学习培训收集数据的问题:“用于自动驾驶等应用的深度学习系统是通过训练机器学习模型来开发的。通常,深度学习系统的性能至少部分地受到用于训练模型的训练集的质量限制。在许多情况下,大量的资源被投入到收集、管理和注释培训数据上。创建训练集所需的工作量可能很大,而且通常是单调乏味的。此外,通常很难收集机器学习模型需要改进的特定用例的数据。”
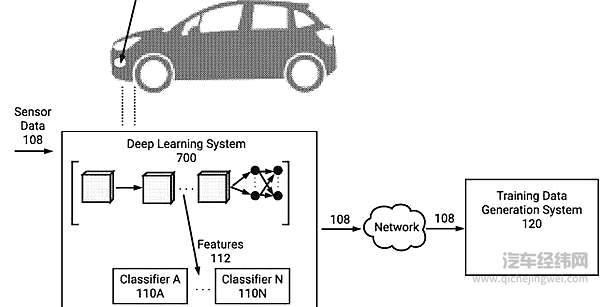
特斯拉开发自动驾驶系统的方式与大多数其他公司大不相同。尽管大多数其他公司利用相对较少的测试车队来收集数据并测试其系统,但特斯拉使用其数十万辆配备了一系列传感器的客户汽车来收集道路和驾驶数据,并在“影子模式”下测试其自动驾驶系统。车队收集的这些数据对特斯拉训练其神经网络实现自动驾驶极其有价值。然而,他们必须小心他们收集并提供给网络的内容。
卡帕西在专利申请中注明:“随着机器学习模型变得越来越复杂,比如深层神经网络,大量训练数据集的必要性也相应增加。与浅层神经网络相比,这些深层神经网络可能需要更多的训练样本,以确保它们的泛化能力较高。例如,虽然神经网络可以被训练成对于所给训练数据来说高度精确,但其可能不能很好地推广到未见的未来示例中。在这个例子中,神经网络可能受益于训练数据中包含的额外示例。”
因此,卡帕西解释了他的专利方法,在传输之前就对源数据进行分类:“示例方法包括接收传感器并将神经网络应用于传感器数据。将触发器分类器应用于神经网络的中间结果,以确定传感器数据的分类器评分。根据至少部分分类器得分,决定是否通过计算机网络传输至少部分传感器数据。一旦确定为阳性,传感器数据就会被传输并用于生成训练数据。”
转载文章,不代表本站观点。
 分享
分享



评论







