 返回
发布
返回
发布





百度 Apollo 的数据会如何开放?
2018-05-10 09:49:48
转眼间,百度的 Apollo 平台已经公布了一年多了。这项声势浩大的自动驾驶开源计划到现在为止已经更新到了 Apollo2.5 版本。
Apollo 平台陆续开放了高精度地图、参考硬件、云计算、视觉感知等众多模块。在最新的 2.5 版本中,Apollo 的方案已经开放了高速公路上的自动驾驶能力,并开始开放车辆控制相关的模块。
对于汽车行业来说,这个迭代速度可以说是非常之快了。
百度 Apollo 的数据开放计划
其实除了迭代速度之外,百度 Apollo 计划还有一个需要重视的举措——开放数据。
自动驾驶的核心在于需要深度的 AI 算法,这又依靠海量大数据和高性能计算。数据分成原始数据、标注数据、逻辑数据和仿真数据四个层次。原始数据由 Lidar、摄象头、雷达、GNSS、IMU、CAN 总线等数据构成。光有原始数据还不够,为了做深度学习养料,要教会机器数据表达的是什么,这就需要标注。进而需要对逻辑的理解和各种模型的刻画。要呈现一个完整的自动驾驶要解决相当多的问题,还需要构建更广泛的场景,重组出无穷的场景,成为仿真数据。

熟悉自动驾驶的人都知道,数据是驱动整个技术优化的核心资源。很多汽车厂商对数据十分珍视,轻易绝不愿意拿出来。
而作为一个开放平台,百度 Apollo 数据作为重要组成部分也开放了出来。在 Apollo1.0 版本发布时,就率先将百度积累多年的数据资源对外开放,包括 2D 红绿灯检测、2D 红绿灯检测及 Road Hackers 等。此后的 Apollo1.5、2.0 及 2.5 版本中,Apollo 的数据开放类型及数据量也都持续扩大。
在今年的 3 月份,百度又公布了一个全新的模块:ApolloScape。你可以把它看作是 Apollo 平台下一个相对独立的「子品牌」。它的本质是一个公开的数据集,包含自动驾驶数据和仿真技术两个部分。

自动驾驶数据将包括具有高分辨率图像和像素级别标注的 RGB 视频,具有场景级语义分割的密集三维点云、基于双目立体视觉的视频和全景图像。数据集中提供的图像为通过采集系统每米采集一帧的方式采集,分辨率为 3384 x 2710。
百度数据采集车是配备了高分辨率相机和 Riegl 采集系统的中型 SUV。采集场景包括不同城市的不同交通状况的道路行驶数据,平均每张图中移动障碍物的数量从几十到上百不等。(例如,单张图像中多达 162 辆交通工具或 80 名行人)
除了采集数据之外,百度还会用自己的视觉感知算法给每一帧画面中的像素做相应的语义分割。当前支持的语义分割种类已经达到了 25 项,包括车辆、行人、自行车、摩托车、道路、交通标识等等。这样的分割有助于开发者可以在这个数据集中直接训练以及验证自己的自动驾驶算法。换言之这套数据集是可以让开发者直接拿来就用的,而不用再做初始的数据解析。
截止到今年 3 月 8 日,百度共发布了包含 74555 帧视频图像序列及对应的逐像素标注和姿态文件。从今年到 2019 年底,百度计划在数据集中陆续加入更改多传感器支持以及更广泛的数据覆盖面。同时,百度还计划在今年年底引入「众包」的数据采集模式,用于收集更多的罕见交通场景。

而在仿真技术上,百度也将逐渐开放行驶轨迹制定,驾驶决策模块,以及感知融合和导航等模块。这也是为了能够更方便的让开发者验证和训练自己的算法。
“ ApolloScape的定位 ”
可以明显的感受到,百度希望通过 ApolloScape 这个数据集吸引到更多的开发者来参与到 Apollo 计划中。但是为何要建立一个独立的子品牌?这里有什么特殊的定位吗?
在 4 月 24 日 ApolloScape 举办的一场学术峰会中,我找到了答案:来参加会议的分享者全部是来自中、美、德、澳等国内外的自动驾驶/机器视觉研究专家。ApolloScape 正在尝试打通自动驾驶产业界和学术界,搭建自动驾驶产学研结合的交流平台。

在自动驾驶领域一直有两个研究方向:落地应用和前沿学术。
落地应用: 主要指的是汽车厂商和零部件供应商,他们更加关注自动驾驶技术如何在现有产品上落地,以及自动驾驶会对汽车行业的商业模式产生怎样的影响。
前沿学术: 主要指的是一些知名高校、研究机构或者是创新科技公司。他们主要关注的是机器视觉、人工智能等技术在自动驾驶推动下的技术革新。
由于落地应用上直接关系到商业利益,因此一般情况下,汽车厂商对于数据的态度都是比较封闭的。
反倒是以高校为主的前沿学术领域,由于大家的目标都是推动技术创新,且相互之间利益关系相对简单。因此对数据开放的接受度很高。
其实在前沿学术领域,已经出现过几个自动驾驶的开放数据集了,最著名的应该就是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办 KITTI。很多研究机构都会在 KITTI 数据集内验证、评估自己的视觉算法。甚至还将 KITTI 作为一个评判标准来做算法排名。
百度这次的 ApolloScape 其实与 KITTI 的定位是一致的,只不过将数据的核心采集点设定在了中国。由于中国在政策以及驾驶环境上的特殊性,一般的研究机构(尤其是海外的)要是想要靠自己在中国获得驾驶数据是非常困难的。而百度这次的数据集就是为这些研究机构提供了便利。
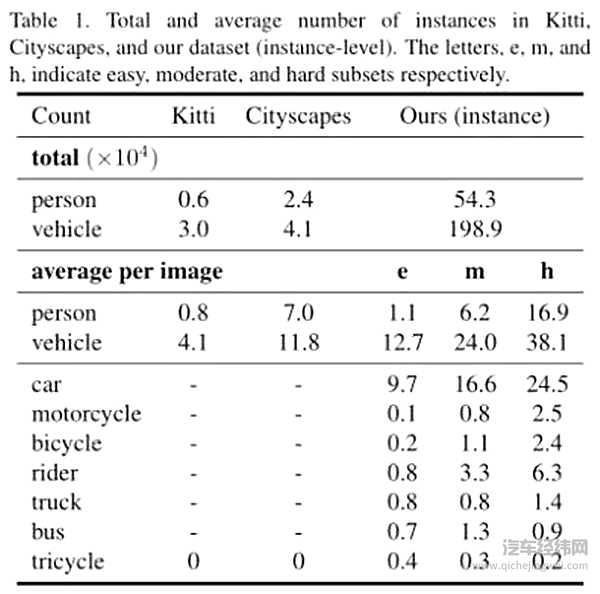
据了解,Apollo 开放平台还与加州大学伯克利分校在 CVPR 2018(IEEE 国际计算机视觉与模式识别会议)期间联合举办自动驾驶研讨会(Workshop on Autonomous Driving),基于 ApolloScape 的大规模数据集定义了多项任务挑战。WAD 已正式于国外知名机器学习竞赛平台 Kaggle 上线 Video Segmentation Challenge(视频场景解析挑战赛),比赛中所提供的数据集中将包含大量的分段原始驾驶图像,包含有 20+种场景标注信息。赛事将持续到 6 月 12 日。目前已有来自全球的三十多只队伍正式报名参加。
其实在自动驾驶领域,应用和学术一直是两个相辅相成的方向。比如在应用领域的标杆企业 Mobileye,其灵魂人物 Shashua 教授同样也拥有着很高的学术地位,从学术领域跳槽到应用企业就职的人也屡见不鲜。
毕竟前沿学术的成果,最终也会落地到实际应用领域,只不过是时间早晚的问题。百度这次的 ApolloScape 计划估计也是在默默地为自己的底层技术创新以及人才聚集做储备。
转载文章,不代表本站观点。
 分享
分享



评论







